Introduction
Cognitive technology allows you to process a lot of information quickly – this is one of the key benefits of the technology. Instead of humans spending hours sorting through information looking for relevant or action-worthy details, cognitive algorithms can surface interesting nuggets in seconds or minutes. In this post I’ll explore one of the key cognitive techniques – called ‘classification’ – and various ways you can apply it to your problem domain.
What is classification?
Wikipedia defines classification as “a process related to categorization, the process in which ideas and objects are recognized, differentiated, and understood”. You can think about classification as “given an input, which output class does it most resemble?”
There are several different ways you might want to classify your information, here are just a few:
- Topic: Is this text about sports or cooking? Is this a legal text or a fictional story? Is this an image of a cat or a dog? Watson Natural Language Classifier is an example solution that helps you answer “where does this belong?”
- Emotion and/or sentiment: Is the speaker happy, sad, or angry? Are they positive, negative, or neutral towards a subject? Watson Tone Analyzer can help answer “how does this user feel?”
- Intent: What is the speaker trying to accomplish? This is an underpinning of conversational systems like Watson Assistant which help determine a user’s goal.
As you can see above, classification can work on a variety of input modalities including images and short or long text. We interchangeably refer to these categories as ‘classes’. The Watson product and services catalog includes several classifier tools including pre-built classifiers like Tone Analyzer and train-your-own classifiers like Natural Language Classifier.
Update: See this post with specific focus on Natural Language Classifier.
Machine learning classification techniques
Machine learning (ML) classifiers are a “no code” way to implement classification. You need only to provide the classes (categories) and examples, and a black box can handle the rest. You may have experience with personal email spam filters. Every time you take an email and “mark as spam”, you are giving an additional training data to a classifier with at least two categories (“spam” and “not spam”).
Machine learning classifiers work well over a wide range of input data. They work best when classifications have distinct boundaries and a large number of ways to be expressed. Email is a great example – there are probably trillions of emails that could be described as spam or not-spam, clearly distinct classifications.
Training an ML classifier requires a “representational set” of training data. If we can provide an accurate sample of data that looks like the broader set, we can train on that smaller sample, giving us much quicker results. Some email spam/not-spam training systems have you get started with just 20 spam and not-spam messages – a far cry from the thousands of emails that might be sitting in your inbox right now, or the trillions that exist world-wide. Enterprise-grade classifiers are trained on subsets as well, just larger subsets. Using an accurate, representational subset is important because machine learning models learn only from example, thus your training set needs to supply all the examples the model needs to learn.
You can try out some pre-trained ML classifiers provided by Natural Language Understanding in the NLU demo service. I tried providing the stirring Gettysburg Address to the NLU demo service and it provided the results below. Be sure to test out the service with your own input data as well.
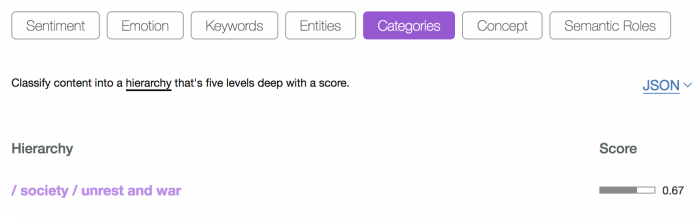
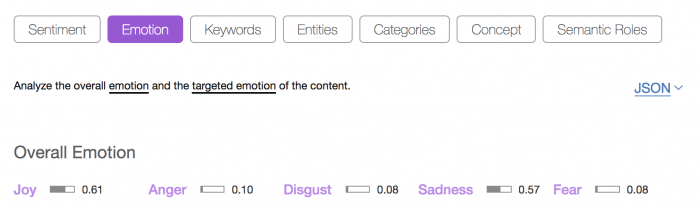
This is a pretty good default classification for a historical eulogy broadly considered the turning point in the American Civil War. Built-in classifiers like the ones used in Natural Language Classification are good for quickly classifying a large amount of data.
When you need to define your own target classes, you can train your own model. One example of this kind of activity is training a conversational chatbot, for instance using Watson Assistant. Chatbots are based on discovering user intents from their utterances, for instance “I want to change my password” has a different intent from “I need to cancel my order” or “How do I get a loyalty card?”. The beginning of training a chatbot by matching utterances to intents is a classification problem. Watson Assistant includes some common intents (and training data) such as eCommerce and customer care, however you can define your own as well. As before, conversational training involves gathering exemplary sample data for each of your target classes.
Rules-based classification techniques
Classification does not always require machine learning – sometimes a simple rule is enough to get the job done. Using rules-based classification is important when you have clear insights/rules that you need applied and you don’t want to leave anything to chance. For example:
- The first three characters of a product code may tell you the manufacturer
- A swear word filterer has a limited set of words that must always be flagged
- A form always contains certain information in precise coordinates (ex: US tax form 1040)
- Use document metadata to find the author name rather than inferring it from the text body
Rules-based classifiers work well when the number of significant input variations is finite. In each example above a definite rule can be identified quickly without a need for a machine learning model to infer it.
Ensemble models
Ensemble modeling is a great way to get the benefits of multiple models. In classification we can use ensemble classifiers to get the best out of both machine learning and rules-based techniques. By running multiple models sequentially or in parallel we can get superior results.
- When classifying document types, we use the machine learning model unless the first nine words are “Form 1040 Department of the Treasury—Internal Revenue Service”
- When classifying email, we use the machine learning classifier first. Then we use a rule check if the sender is on a known whitelist or blacklist.
- When classifying text for obscenity, we let the machine learning analysis run first and then double-check against our rules list of known swear words.
We can even run multiple classifiers in parallel, “competing” against one another, and then use a resolution mechanism such as voting to decide which result we want to use.
As alluded in the examples above, one important reason to use ensembles is to take advantage of additional context. In the email classification mechanism we use a machine learning model on the email subject + body and then use rules on the sender’s address. When classifying text you may be able to get better insight by including aspect of the user’s profile. For instance when classifying my Twitter activity you might start with the default assumption that each tweet is about technology, since my profile tells you I tweet about technology. When accuracy is paramount in your classification, use all the context that is available to you.
Conclusion
Classification is intended to help you organize objects and information. Cognitive technologies allow you to do this classification quickly and in many cases with no coding required. For best classification results you need to understand your inputs and whether they have a finite or infinite number of significant differences. Use machine learning when you want to train by example and use rules when you have finite, clearly defined rules available. You can combine multiple classification techniques in an ensemble to get the best results, particularly when there is additional content that cannot be directly fed into a classifier.
1 Comment