If you’ve built a cognitive system, you know that it requires a lot of training to reach peak performance. (For details, read Why does machine learning require so much data?) How much training data do you really need? And when can you stop collecting training data?
The answer is: “it depends”. But, you can make an educated guess by plotting the performance of your cognitive system against the size of your training set. When performance starts to plateau (at some point, it definitely will). After this point the cost of performance improvements greatly increases.
I recently showed you how to an NLP model with machine learning and how to improve the performance of that model. I continued training that model for a total of five iterations and plotted the performance as seen below:
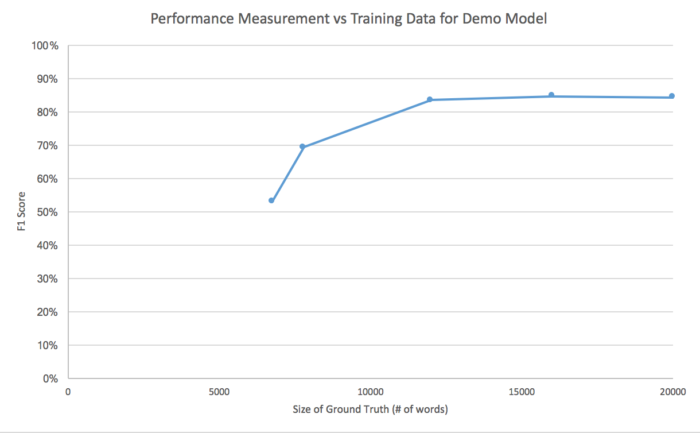
The absolute values on the scales are not as important as the overall shape of the curve. Machine learning can make rapid progress with limited amounts of training data, and can make large jumps in accuracy by going from a tiny data set to one that is merely small. The model above made a huge improvement (16 points on F1 scale) when the ground truth increased by a modest 1000 words (a single-spaced, double-sided printed page).
The model above also plateaus at approximately 12,000 words of ground truth. I spent a few evenings curating 8,000 more words of ground truth and was rewarded by a tiny 0.8 point increase in F1. Having observed this plateauing I will declare success at 84% F1, which is a fabulous result for my overall level of effort.
Depending on your use case you may decide it is worth chasing additional accuracy performance. In my cognitive systems testing series, I talked about how to check each component of the system to improve performance, since 100% accuracy is not possible. Don’t limit yourself to looking at just one system, see if you can get additional information from other systems or subsystems. In my NLP model I only considered plain text from Wikipedia articles, but I could have decided to have created a parallel system that looked at the links/citations within those articles. Or I could decide it is sufficient to identify documents/paragraphs containing entities I care about.
In conclusion, cognitive performance increases with additional training data until you reach a performance plateau. It’s a good idea to measure your performance against training data size to determine when you can stop collecting data.
Andrew, I always though ML performance improved steadily over time and this bell curve was more a rules based result. Are you saying both rules based and statistical model based performance improvement follow this bell curve where small improvements in Training data (for stat) and perhaps low hanging fruit updates to rules can produce significant improvement to accuracy?
In short, yes. You can definitely max out a ML model performance once you have built your best training set – one that best represents the variability in your real world data. That is why a statistic model can still benefit from a rules-based assist. Extreme/edge cases is a great place for rules to help close the gap in a statistical model.