AI systems are inherently probabilistic. We can add deterministic logic on top of a probabilistic response, and in fact combining deterministic rules and probabilistic machine learning is a common and good idea. Frequently I see a pattern used where a rule is executed based on the confidence of a machine learning model’s prediction – if confidence is above or below a certain threshold value the prediction is treated differently. In this pattern care needs to be chosen to select a proper threshold value.
There are multiple ways thresholds may be used in machine learning model:
- In a chat application, how confident is the model that it determined the user’s primary intent? (Or possibly, detecting a compound intent?)
- In a voice application, how confident is the model that transcription of an audio matches the words the user actually spoke?
- In a prediction model, how confident is the model that the prediction is correct? Or that the prediction is “close enough”?
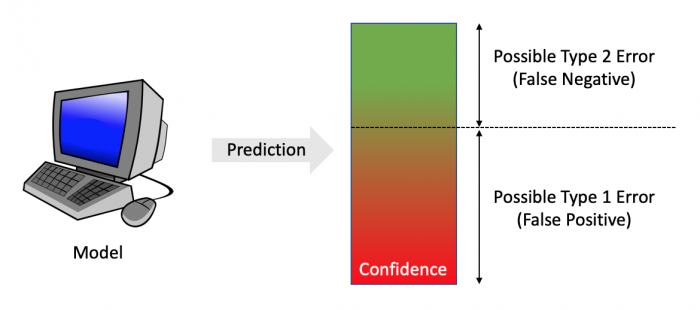
In the chat and voice examples above, I may use a threshold to decide if I should ask the user to confirm the output from the model. In the prediction example, I may automatically accept high-confidence predictions or send low-confidence predictions for manual human review. Using a threshold gives me additional control over the user experience when my model is used.
Setting the threshold too high or too low has an influence on user experience. If the threshold is too low, our chat users will very frequently be asked to confirm the system understood their intent, and this can be aggravating for users. If the threshold is too high, the chat system may answer a question that the user didn’t ask!
Mistakes are possible no matter what level the threshold is set. It is inevitable that some low-confidence results will be correct and that some high-confidence results will be incorrect. From basic probability, even an event with 99.9% likelihood will not happen one in a thousand times.
There is a balance between at what threshold you should set the confidence bar at. This balance is influenced by the cost of two types of errors.
- Type 1 (False positive): You predicted or detected something that was not there.
- Type 2 (False negative): You failed to predict/detect something that was there.
(Aside: False positives hurt precision, false negatives hurt recall. I previously wrote about balancing precision and recall in NLP context.)
In all three previous examples our threshold was used to predict “was the model’s prediction correct enough to use” based on the model’s confidence in its prediction. A false positive in this case is that because of a below-threshold-confidence answer, we decided not to trust the answer, even though it was correct. A false negative then is when an above-threshold-confidence answer is trusted even when it was wrong.

When setting a threshold you need to have a clear understanding of the costs of both False Positive and False Negative errors. If some number of False Positives are annoying to end users, but the same number of False Negatives is illegal, there must obviously be a high threshold! The stakes will likely be different in your domain. You need to set a threshold with a clear understanding of both the costs and the mitigation strategies for mistakes.
Note that you can always eliminate one class of error entirely by setting an extreme threshold. At threshold = 1, we always prompt the user for clarification, or never trust the model, and thus we are quite sure of the result. At threshold = 0 we always trust the model, this is expedient if you can deal with the mistakes. For chatbots, one strategy for mistakes in threshold=0 is to end a conversation with “is there anything else?”, this way if you miss the intent you at least give a chance for it to be presented again.
For most applications an extreme threshold does not make sense. The remaining question is where to set the threshold. Best practice is to make a reasonable estimate for the initial threshold level and to adjust the threshold higher or lower based on observing the model or application and objectively assessing the error rates from the threshold. There is generally a sweet spot that minimizes not just total errors but cost from error as well.